关嘉伟 · 趋境科技
01 / 16

2026 中国生成式 AI 大会(北京站)
端云结合,
端云结合,
让 OpenClaw
更有趣也更安全
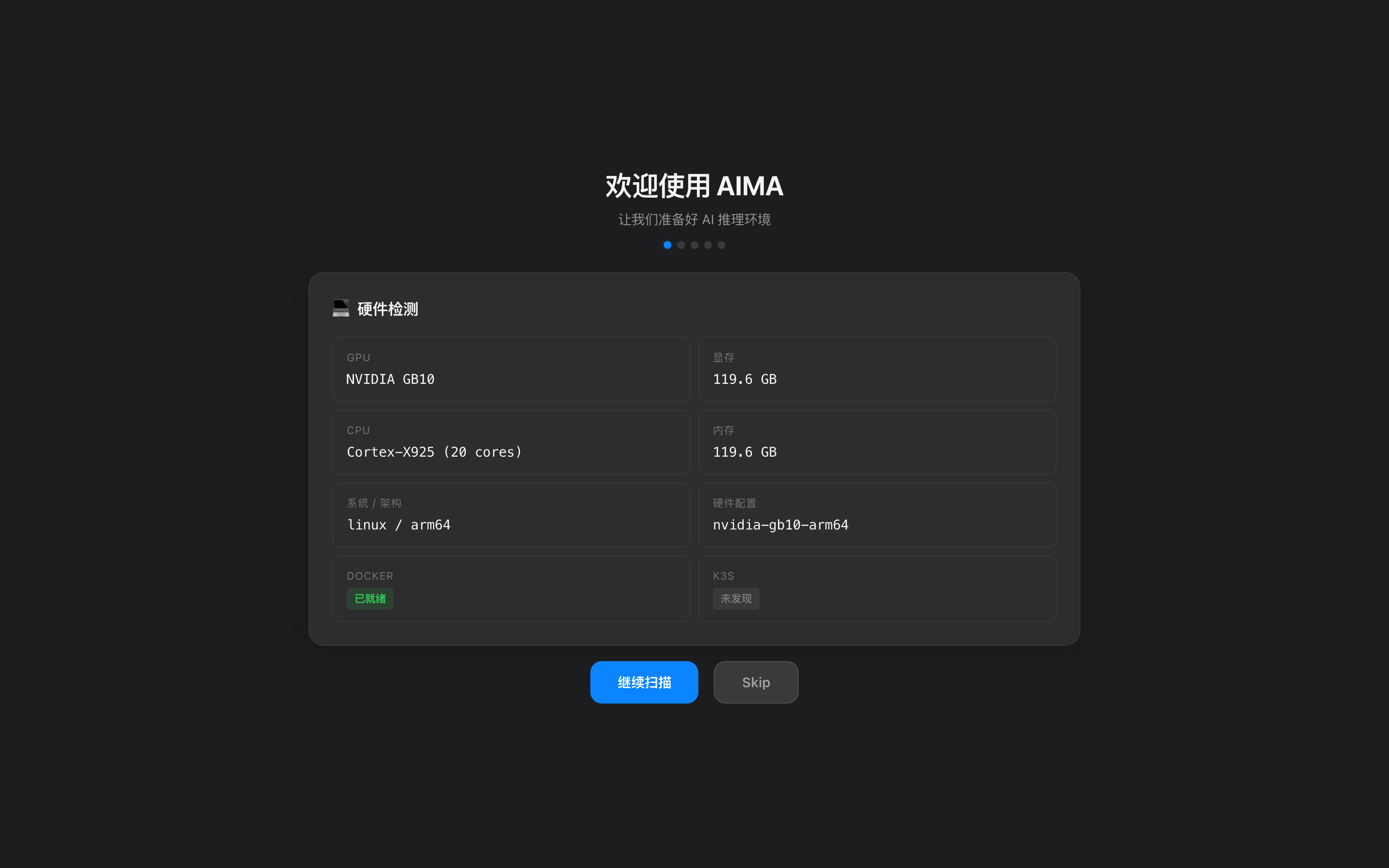
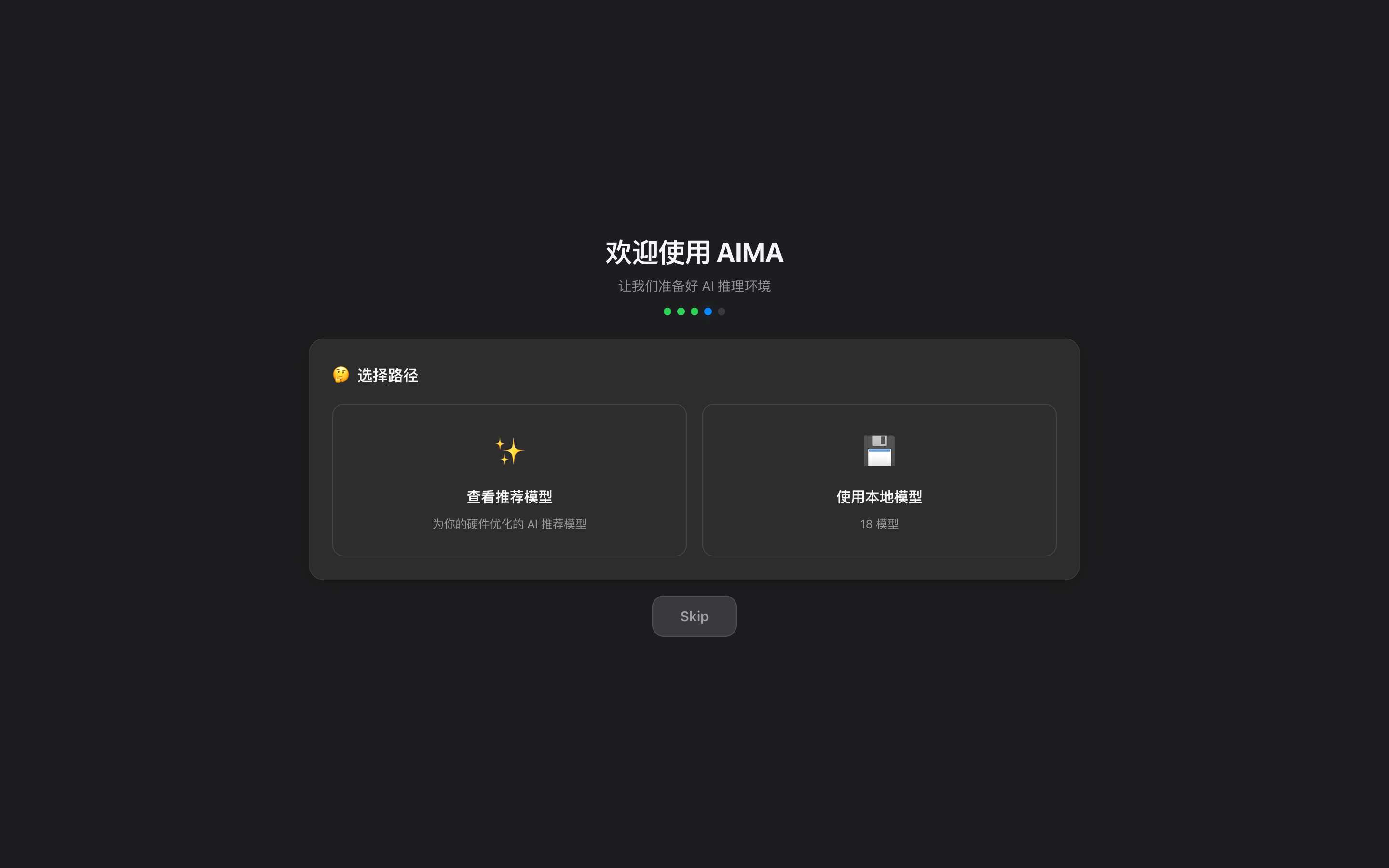
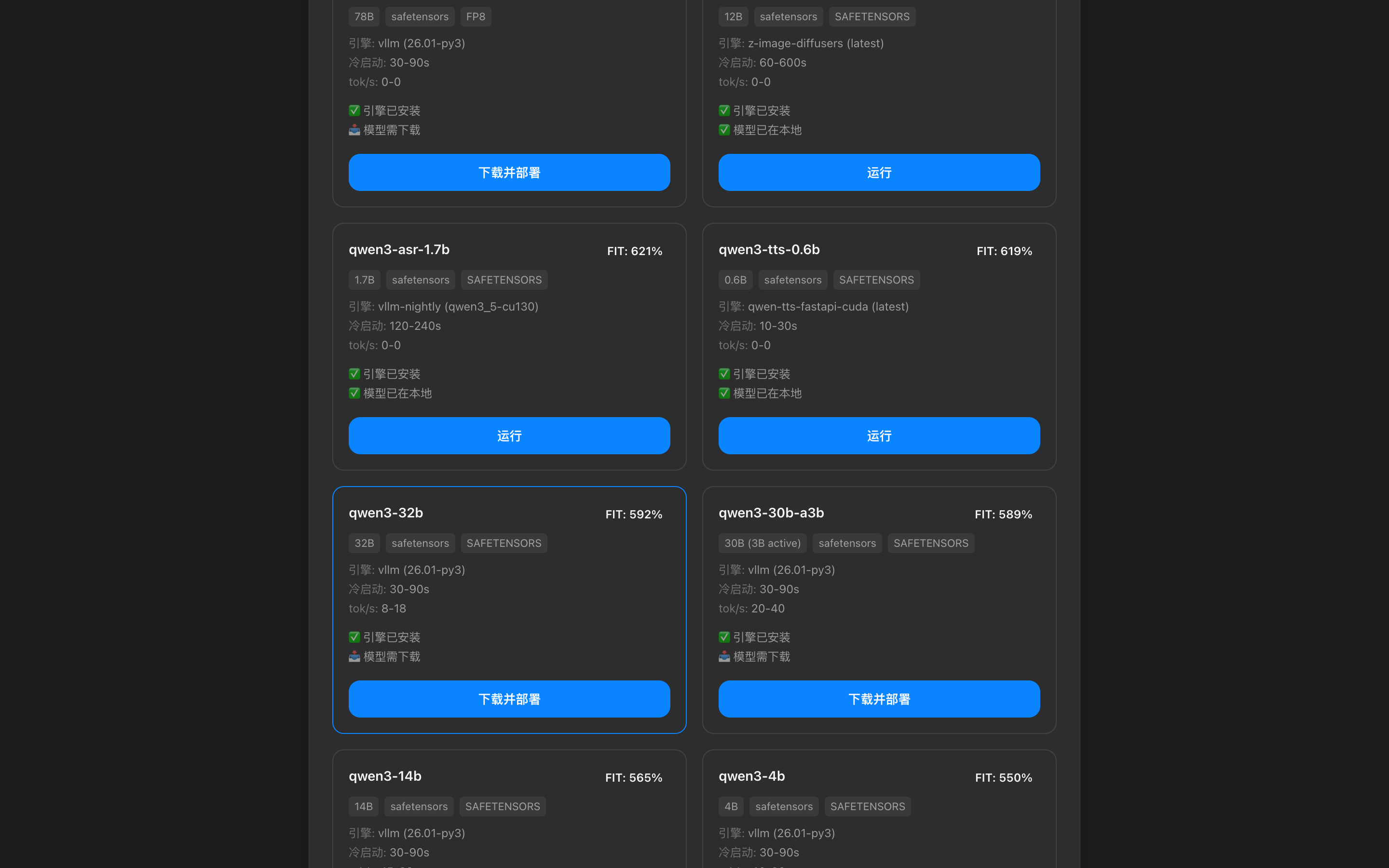
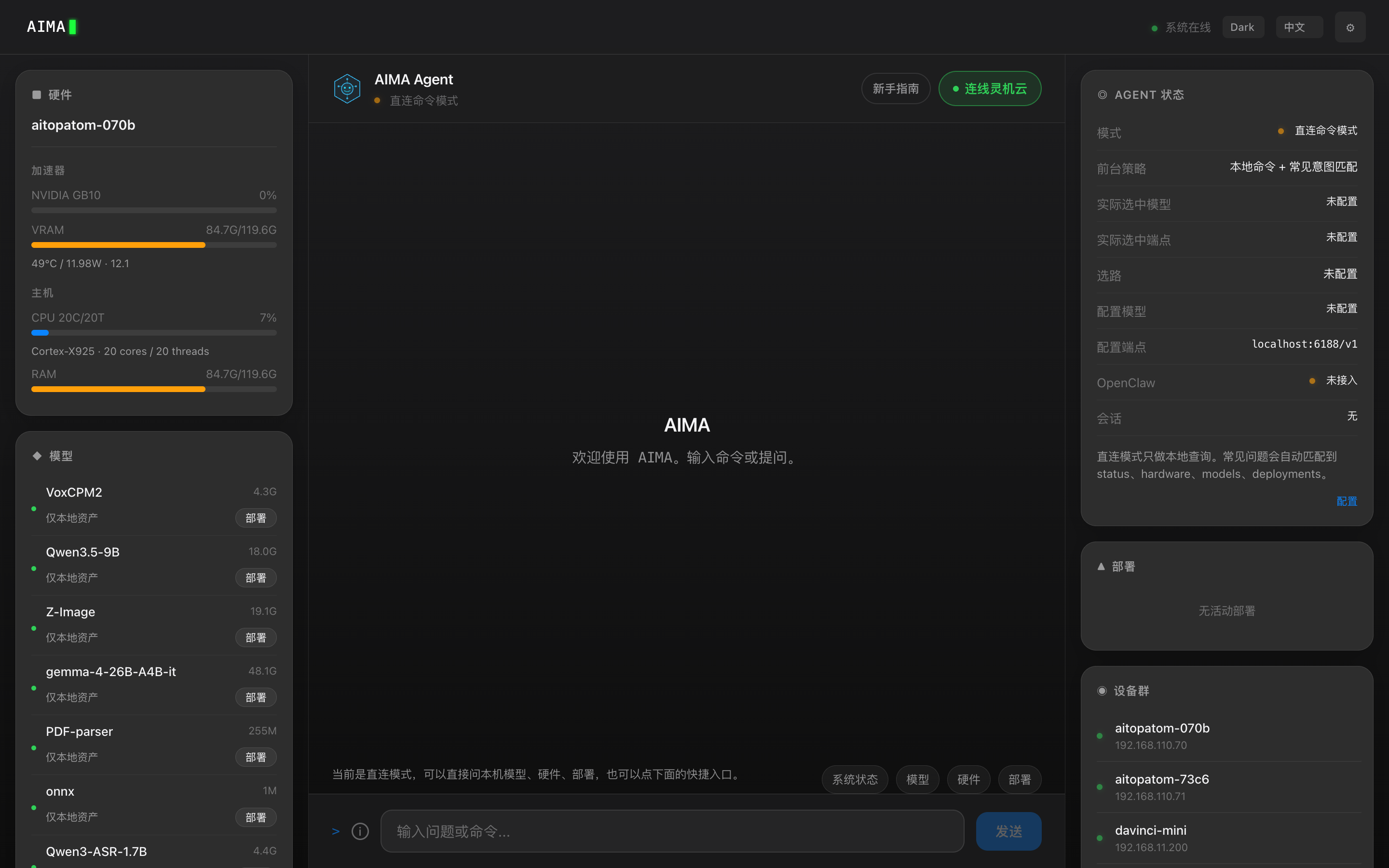
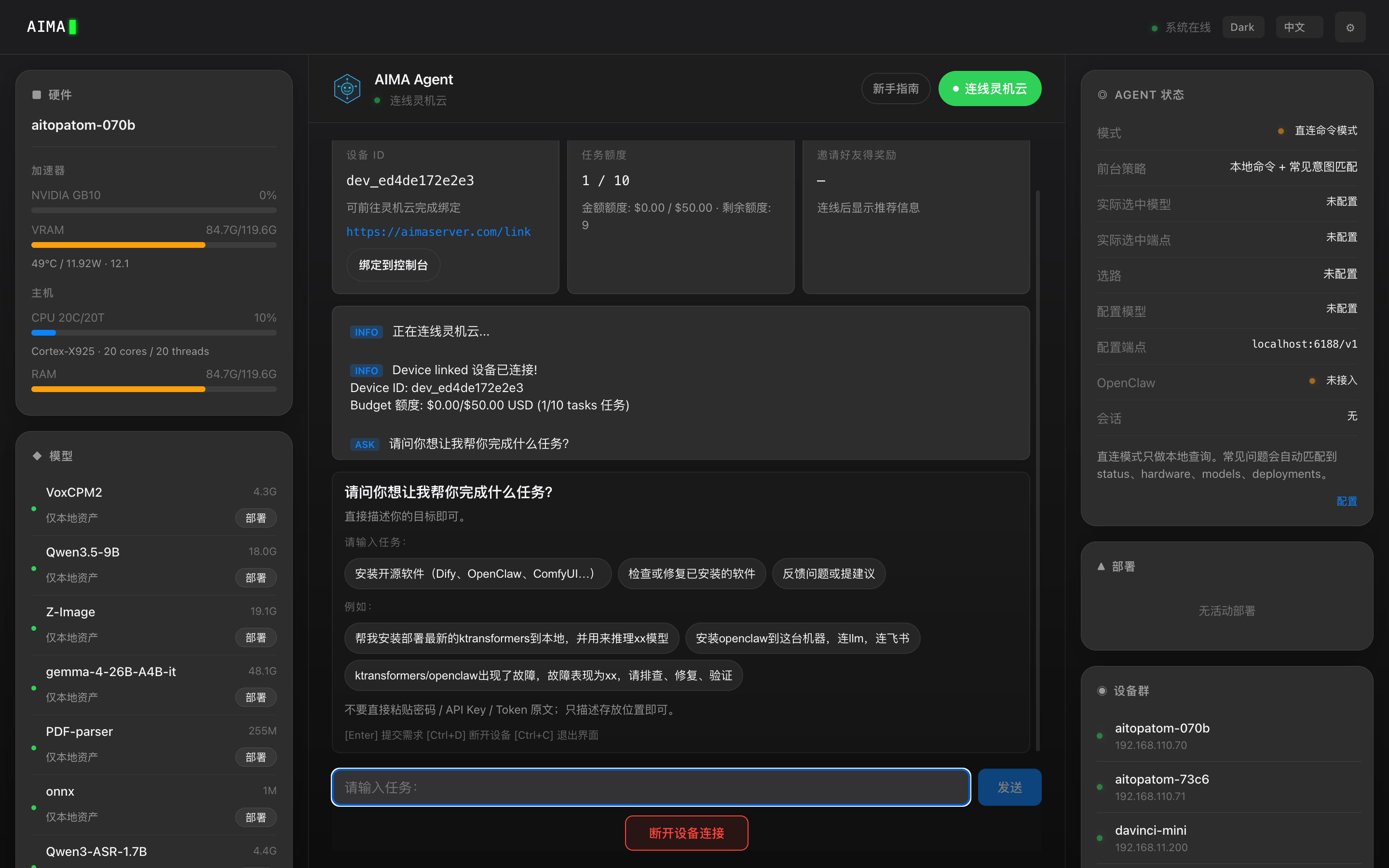
硬件载体在变
端上跑得动多模态和隐私数据,云上有真正聪明的模型
两边走到一起,事情才刚开始有意思
关嘉伟
趋境科技副总裁
OpenClaw 技术研讨会
2026 · 端云协同